
Ensemble model
20 Dec 2017 | ensemble원본 : How to build Ensemble Models in machine learning?
지난 12개월 간 다양한 머신 러닝 해커톤에 참여해왔다. 시합이 끝나면 항상 1등의 솔루션을 확인해보는데, 보다보면 굉장한 insight 를 받기도 해서 차후 시합에 큰 도움이 되곤 했다.
우승자들의 대부분은 잘 튜닝된 개별 모델의 앙상블(Ensemble) 과 더불어 feature engineering 을 사용하고 있었다.
이 두 방법을 잘 기억하기를 조언한다. 머신 러닝에 있어서 이 것들을 잘 사용하는 것이 아주 중요하기 때문이다.
나는 대부분의 경우 feature engineering 은 잘 사용해왔지만, 앙상블은 사용하지 않았다. 만약 당신이 초보자라면 앙상블 모델에
최대한 빨리 익숙해지는 것이 좋을 것이다. (어쩌면 무의식 중에 이미 적용중이었을 수도 있다!)
이 포스트에서 앙상블 모델링의 기초에 대해 설명하고자 한다. 그리고 나서 앙상블의 장단점을 살펴보고, 실습을 제공할 것이다.
1. Ensemble 이란?
일반적으로 앙상블이란 2개 이상의 알고리즘 - base learner 라고 함 - 들을 결합해서 사용하는 기술을 의미한다. 모든 base learner 들의 예측 결과를 조합하여 사용하기 때문에 전체 시스템을 보다 탄탄하게 해준다. 여러명의 주식 거래자들이 한 방에 모여 주가가 오를지 내릴지를 토론하여 결정하는 것과 마찬가지라고 생각하면 되겠다.
각각의 거래자들이 모두 다른 정보와 이해를 가지고있기 때문에, 문제 상황으로부터 결론에 이르기까지의 공식은 다 다를 것이다. 따라서 주식 시장에 대한 각자의 이해를 바탕으로 다양한 주가 예측이 나오게 된다.
이제 최종 결론을 내릴 때가 되면 모든 다양한 예측들을 함께 고려해봐야할 것이다. 이로 인해 우리의 최종 결론은 더욱 탄탄(robust)하고, 정확하고, 덜 편중(biased)된 방향으로 결정될 수 있다. 최종 결론은 거래자 개인의 판단에 기반한 결론과 정 반대의 내용이 될 지도 모른다.
또 다른 예로 구직자의 인터뷰를 들 수 있다. 구직자가 가진 능력에 대한 최종 판단은 인터뷰 진행자들의 모든 피드백에 기반하여 결정된다. 인터뷰 진행자 한 명만으로는 요구 기술과 특성 각각에 대한 테스트를 모두 수행하지는 못할 수 있다. 하지만 여러명의 인터뷰 진행자들의 복합적인 피드백으로 인해 구직자에 대한 더 올바른 평가가 이루어 질 수 있는 것이다.
2. Types of ensembling
더 세부적으로 진행하기 전에 꼭 알아야하는 기본 컨셉들이 있다:
-
Averaging :
모델들의 예측 결과에 대한 평균을 취하는 것으로, regression 문제나 classification 확률 예측 문제에 모두 사용된다.
-
Majority vote :
classification 문제를 해결할 때, 각각의 모델이 선정한 결과 중 최대 빈도로 선택된 결과를 취하는 방식이다.
-
Weighted average :
Average 값들에 모델 별 가중치를 두는 방식이다.
여러 개의 모델들을 조합하는 방법은 셀 수 없이 많을 것이다. 하지만 주로 사용되는 기술들을 소개한다:
-
Bagging
Bagging 은 Bootstrap aggregation 이라고도 불린다. Bagging 을 이해하기 위해서는 먼저 bootstraping 을 이해할 필요가 있다. Bootstraping 은 n 개의 행을 가진 원본 dataset 으로부터 n 개의 행을 선택하는 샘플링 기법이다. 핵심은 각각의 행이 선택될 때 동일한 확률로 선택된다는 것이다.
Original dataset
1st sampling
2nd sampling
3rd sampling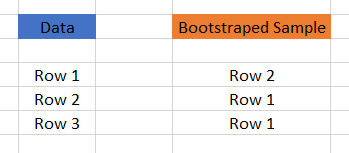
랜덤하게 선택하기 때문에, 위와 같이 중복 선택이 허용된다.동일한 원본 data 로부터 여러개의 bootstrapped sample 들을 추출할 수 있는데, 추출된 sample 로부터 또 다시 bootstraping 을 하면 tree 구조의 많은 sample set 을 구성할 수 있다. 그러한 sample set 을 기반으로 majority vote 나 averaging 기법을 사용해서 최종 예측을 얻을 수 있다. Bagging 이란 이렇게 동작하는 것이다.
여기서 눈여겨 보아야 할 것은, bagging 을 통해 분산(variance)를 줄일 수 있다는 점이다. Random forest 가 사실 이러한 컨셉을 사용하는데, Random forest 는 한 발 더 나아가 각각의 bootstrap 된 sample 들의 feature subset 까지 랜덤하게 추출함을 통해 분산을 줄인다. 이를 통해 학습 데이터를 구분(split) 할 수 있다.
-
Boosting
Boosting 은 여러개의 알고리즘을 순차적으로 적용하는 기법으로, 첫 번째 알고리즘이 전체 dataset 에 대한 학습을 진행하고, 다음 알고리즘들은 첫 번째 알고리즘이 실패한(남긴, residuals) 데이터에 맞추어 생성되는 방식이다. 따라서 다음 알고리즘들은 이전 모델이 잘 예측하지 못한 데이터에게 더 큰 가중치를 두게 된다.
이는 전체 dataset 에 대한 성능은 좋지 않지만, 특정 부분에 대한 성능은 좋은 learner 들의 집합으로 이루어진다. 따라서 각각의 모델이 모여 앙상블 전체의 성능을 향상(boost) 시키는 것이다.
여기서 중요한 부분은, boosting 은 편중(bias) 를 줄이는 데에 집중한다 는 점이다. 이로 인해 boosting 은 오버피팅을 유발하기 쉽다. 따라서 boosting 사용 시, 오버피팅을 피하기 위한 파라메터 튜닝이 굉장히 중요하다.
Boosting 의 대표적인 예제로는 XGBoost, GBM, ADABOOST 등이 있다. -
Stacking
Stacking 은 여러개의 머신 러닝 모델들을 쌓아서 각각의 모델이 예측 결과를 상위 레이어의 모델에 전달하고, 최상위의 모델이 최종 결론을 도출하는 방식이다.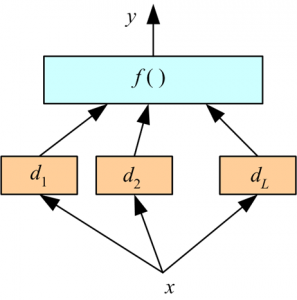 위 그림에는 두 개의 머신 러닝 모델들이 존재하고 있다:
위 그림에는 두 개의 머신 러닝 모델들이 존재하고 있다:- 하위 레이어의 모델들(d1, d2, d3) 는 원본 입력 feature들(x) 를 취한다.
- 최상위 모델 f() 는 하위 레이어 모델의 출력을 받아 최종 출력을 예측한다.
- 주목할 점은 예측된 결과 값들이 학습 data 로 사용된다는 점이다.
위에서는 2 개의 레이어만 사용되었지만, 다양한 수의 레이어가 사용될 수 있고, 레이어 내의 모델 역시 개수에 제한이 없다. 모델들을 선택함에 있어 두 가지 핵심 요건이 있는데:
- 개별 모델들은 정해둔 정확도 요건(criteria)을 충족시킬 것.
- 개별 모델의 예측 값은 다른 모델의 예측과 큰 연관도(correlation)가 없어야 한다.
최상위 모델은 하위 모델의 예측 결과를 입력값으로 받고 있는데, 이 최상위 모델 또한 아래와 같은 단순한 모델로 대체될 수 있다:
- Averaging
- Majority vote
- Weighted average
3. Ensemble 의 장단점
3.1 장점
- 앙상블은 모델의 정확도를 높이고, 대부분의 case 에 대해 잘 동작한다고 입증된 방식이다.
- 거의 모든 머신 러닝 해커톤에 있어서, 1위를 하는데 필수적이다.
- 앙상블은 모델을 더욱 탄탄하고 안정적이게 해주고, 따라서 대부분의 시나리오에서 괜찮은 성능을 보장해준다.
- Data 에 내재하는 선형적이고 단순한 관계 뿐 아니라 비선형적인 복잡한 관계까지 뽑아내는 데에 앙상블을 사용할 수 있다.
2 개의 다른 모델을 사용해서 하나의 앙상블을 구성하면 된다.(?)
3.2 단점
- 앙상블은 모델의 해석력(interpretability)을 떨어뜨리고, 결국 비지니스 insight 를 이끌어내기가 굉장히 힘들어 질 수 있다.
- 시간이 많이 걸리고, 실시간 어플리케이션 용으로는 적합하지 않을 수 있다.
- 앙상블을 구성하는 모델을 잘 선택하는 방법을 익히는 것이 어렵다.
4. 예제
생략