
Entropy, Cross-entropy and KL-divergence
19 Feb 2018 | entropy, cross entropy영상 : A Short Introduction to Entropy, Cross-Entropy and KL-Divergence
위 링크 영상에서 Entropy, Cross-entropy, KL-divergence 에 대해 이해하기 쉽게 설명을 해주고 있어, 정리 차원에서 작성해봅니다.
불확실성(Uncertainty) 과 bit
Entropy, Cross-entropy 의 개념은 미국의 수학자이자 암호학자인 Claude Shannon 의 1948년 논문 “A Mathematical Theory of Communication” 으로부터 시작되었습니다. 그는 논문에서 현재의 정보 이론(Information Theory)으로 불리는 개념을 처음 소개하였습니다. 디지털 통신에서 메세지는 bit 들로 이루어져 있는데, 알다시피 0 또는 1로 구성됩니다. 하지만 모든 bit 가 유용한 정보를 포함하지는 않습니다.
Shannon 은 자신의 이론에서 이렇게 설명합니다.
1 bit 의 정보를 전송하는 것은, 수신자의 불확실성을 2로 나누는 것을 의미한다.
직관적으로 잘 이해가되지는 않지만, 일기예보의 예를 들어보겠습니다. 내일 비가 올 확률이 50%, 맑을 확률이 50% 라고 합시다. 만약 기상청에서 내일 비가 온다고 예보를 했다면, 이는 우리의 불확실성을 2로 나눈 셈입니다. 같은 확률의 2가지 가능성이 있었는데, 예보로 인해 이것이 1로 줄었기 때문이죠. 따라서 기상청은 실제로는 1 bit 의 유용한 정보를 보낸 것이라고 할 수 있습니다. 이것은 실제로 이 정보가 어떻게 인코딩되었는지와는 무관합니다. “Rainy” 라는 문자열로 전달되었다면 데이터의 크기는 40 bit 이겠지만 실제 유용한 정보는 1 bit 인 것이죠.
그럼 내일의 날씨를 8 가지로 구분할 수 있다면 어떨까요?
예를 들면 ‘맑음, 약간 흐림, 흐림, 많이 흐림, 약간 비, 비, 많은 비, 천둥번개’ 라고 할 수도 있겠죠.
따라서 기상청이 내일의 일기 예보를 우리에게 보낸다면, 이는 우리의 불확실성을 8로 나눈 것이라고 할 수 있습니다.
8은 2의 3승이니까, 이 일기 예보는 3 bit 의 유용한 정보를 보낸 셈이죠.
이렇게 보면 ‘실제로 전달된 정보’의 bit 수를 계산하는건 간단해 보입니다. 불확실성을 줄여주는 인수(factor) 값에 로그2 를 씌워주면 되겠죠.
위 예제라면, 아래 식으로 설명될겁니다.
지금까지 설명한 것은 각각의 날씨들이 모두 같은 확률로 발생할 수 있다고 가정했는데요,
각각의 확률이 다르다면 어떻게 될까요?
예를 들어, 내일 비가 올 확률이 25%, 맑을 확률은 75% 라고 해봅시다.
이 때 기상청에서 내일 비가 올 것이라고 예보했다면, 이로 인해 우리의 불확실성은 1/2 이 아니라 1/4 로 줄었다고 할 수 있습니다.
불확실성이라는 개념이 조금 헷갈리지만, 50%, 50% 의 가능성을 가진 결과에서 하나를 예측한 것보다는 25%, 75% 의 가능성의 가진 결과 중에 25% 일 것이라고 예측하는 쪽이 더 많은 불확실성을 낮춰줬다고 말하는게 당연하겠죠.
만약에 비가 거의 오지 않는 사막에서 (비 올 확률 1%), 내일의 일기 예보가 ‘비’ 라고 한다면, 이는 불확실성이 1/100 로 훨씬 많이 줄어들었다고 할 수 있을 것입니다. 즉, 같은 ‘비’ 예보라고 하더라도, 비 올 확률이 50% 인 장소에서의 의미와, 1% 인 장소에서의 의미는 다를 것입니다. 당연히 1% 인 곳에서는 더 많은 불확실성이 해소된거죠.
Entropy
위 설명을 공식화해서 설명해보면,
불확실성이 감소되는 크기는 어떤 이벤트의 발생 확률의 역수와 같다.
라고 할 수 있습니다. 위 예제의 경우, 25% 의 역수이므로,
$ 1 / 0.25 = 4$ 이고, 따라서 $ log_2(4) = 2 $ 이니까 2 bit 의 정보가 필요한게 됩니다. 이 때 역수의 log 는 - 를 붙이는 것과 같으니까,
$ log_2(4) = -log_2(0.25)$
로 정리할 수 있겠네요.
만약 위 예제에서 기상청이 내일 날씨가 맑을거라고 예보하는 경우, 불확실성은 그렇게 많이 낮아지지 않을겁니다.
$ -log_2(0.75) = 0.41 $
즉, 0.41 bit 가 됩니다. 0.41 bit 만큼의 정보를 얻을 수 있다는 뜻이죠.
그럼 기상청으로부터 얻을 수 있는 정보의 평균값은 얼마일까요? 각각의 이벤트에 대한 기대값을 계산해보면,
$ 75\% * 0.41 + 25\% * 2 = 0.81 \text{ bits} $
즉, 평균적으로 우리는 매일 기상청으로부터 0.81 bit 의 정보를 얻을 수 있다고 할 수 있습니다.
이것이 바로 Entropy 입니다. Entropy 는 어떤 이벤트가 얼마나 불확실한지 를 설명하는 아주 훌륭한 방법입니다.
위 공식이 완전히 이해가 되죠? 요약하자면,
Entropy 는 주어진 확률 분포 p 에서 하나의 샘플로부터 얻을 수 있는 정보의 평균량이다.
라고 할 수 있을 것입니다. 이는 해당 확률 분포가 얼마나 예측하기 힘든지를 의미합니다.
만약 우리가 거의 항상 날씨가 맑은 사막 한가운데에 살고 있다면, 일기 예보로부터 얻을 수 있는 정보는 많지 않습니다.
Entropy 는 거의 0에 가깝겠죠?
반대로 날씨가 변화무쌍한 곳이라면 Entropy 값은 훨씬 클 것입니다.
Cross-entropy and KL Divergence
그럼 Cross-entropy 는 뭔지 얘기해볼께요. 사실 아주 간단한 개념입니다.
바로 메세지 길이의 평균값 입니다. 위에서 설명했던 8가지 날씨 예제에서, 기상청이 아래와 같은 3 bit 의 정보를 사용한다고 해보죠.
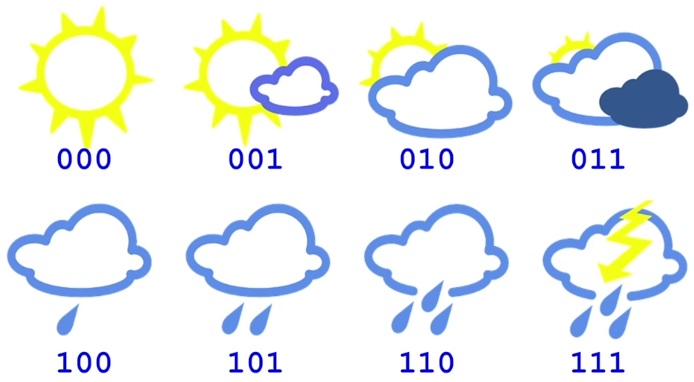
이 경우 메세지의 평균 길이는 당연히 3 bit 입니다. 그게 Cross-entropy 입니다.
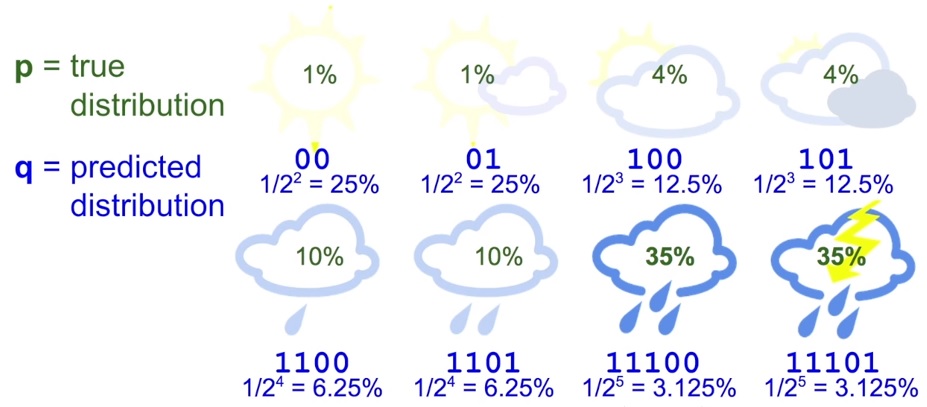
하지만 이것은 각각의 확률이 같다고 가정한 경우이고, 만약 아래 그림처럼 각각 날씨에 대한 확률이 다른 경우는 어떨까요?

이 경우 Entropy 를 계산해보면,
즉, 실제 유용한 정보는 2.23 bit 뿐임을 알 수 있습니다. 그럼 아래처럼 변경하면 어떨까요?

이제 각각의 날씨에 대한 메세지의 길이를 달리 했습니다.
이렇게 하면 연속된 bit 들에 대해서도 간단하게 해석이 가능해집니다.
예를 들어 011100 이라는 메세지는 01 + 1100 만으로 분리 가능하기 때문이죠.
이때 Cross-entropy 를 다시 계산해보면,
$ 35\% * 2 + 35\% * 2 + 10\% * 3 + \text{…} + 1\% * 5 = 2.42 \text{ bits} $
이렇게 Cross-entropy 를 개선시켰습니다. 하지만 3 bit 보다는 낫지만 2.23 bit 까지는 낮추진 못했죠.
아무튼 이번엔 이 방식을 다른 장소에 적용해보면 어떨까요? 아래처럼 항상 비가 오는 곳이라고 해보죠.

이 때의 Cross-entropy 를 계산해보면, 4.58 bit 라는 값이 나오게 됩니다.
굉장히 안좋은 결과네요. 거의 entropy 의 2 배에 가깝습니다.
다시 말하면, 이 경우 평균적으로 4.58 bit 가 전송되지만 실제로는 2.23 bit 만이 유용하다는 의미입니다.
이는 우리의 코드가 날씨의 분포에 대해서 가정(assumption) 을 내포하고 있기 때문입니다.
예를 들어, 맑은 날씨를 2 bit 메세지로 전송하겠다는 것은 최소한 4일에 한 번(2 의 2 승)은 날씨가 맑을 것이라는 걸 내포하고 있습니다.
즉, 우리의 코드는 25% 확률로 날씨가 맑을 것이라는 암묵적인 예측을 하고 있는 셈입니다. 그게 틀린다면 우리의 코드는 최적화될 수 없겠죠.
따라서 예측된 분포 q 는 실제 분포 p 와 차이가 발생할 수 밖에 없습니다.
이제 Cross-entropy 를 실제 확률 분포 p 와, 예측된 확률 분포 q 의 공식으로 설명이 가능해집니다.
보시다시피 Entropy 공식과 비슷하지만, 실제 분포 p 의 log 대신 예측된 분포 q 의 log 를 사용하고 있습니다.
여기서 $ log_2(q) $ 는 메세지의 길이죠.
만약 우리의 예측이 완벽하다면, 즉 예측된 분포가 실제 분포와 동일하다면, Cross-entropy 는 Entropy 와 같은 값을 가질 것입니다.
하지만 분포가 차이날수록 Cross-entropy 는 Entropy 보다 더 큰 값이 되겠죠.
이와 같이 Cross-entropy 와 Entropy 의 차이를 Relative Entropy 라고 부르고, 더 일반적으로
Kullback-Leibler Divergence (KL Divergence) 라고 부릅니다.
공식으로 적어보면,
위의 예제에서, Cross-entropy 는 4.58 bit 이고 Entropy 가 2.23 bit 였으니까 KL Divergence 는 2.35 bit 가 되겠네요.
Cross-entropy in Machine Learning
이미지 분류 모델에서, 모델이 예측한 결과를 q 라고 생각하면 됩니다.
그리고 실제 분포 p 는 주어진 label 로부터 계산하면 되겠죠?
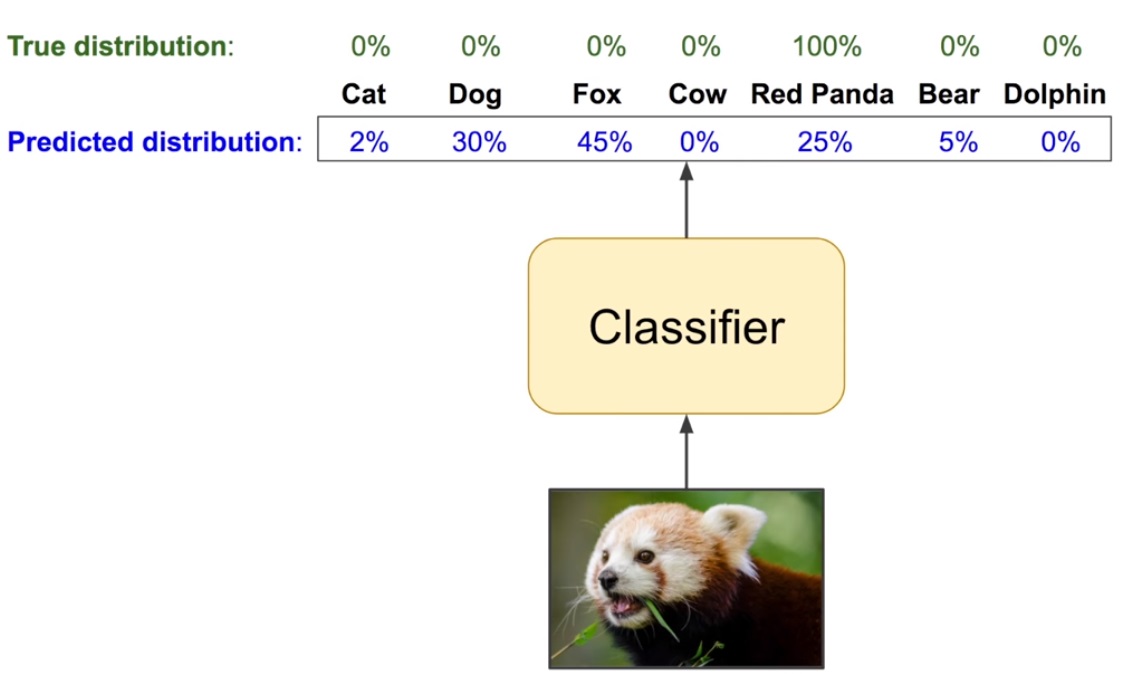
분류 모델에서 왜 Cross-entropy Loss 가 사용되는지 이제 잘 알 수 있을 것입니다.
여기서 이진 log 가 아닌 자연 log 가 사용되었는데, 이는 모델 학습 시 차이가 없기 때문입니다.
이진 log 는 자연 log 를 상수로 나눈 것일 뿐이니까요.
위 그림의 경우 Cross-entropy loss 값은 $ -log(0.25) = 1.386 $ 으로 굉장히 큰 값을 나타내고 있네요.
예측된 분포가 실제 분포와 같아질수록 loss 는 0 에 가까워 질 것입니다.
끝.